
利用spleeter分离歌曲人声并借助Parselmouth绘制声波图像
环境准备
Python >=3.7
Python IDE (本文使用PyCharm)
本次演示采用最快速的方式获取结果
提取人声
软件提取【推荐】
https://makenweb.com/SpleeterGUI
下载
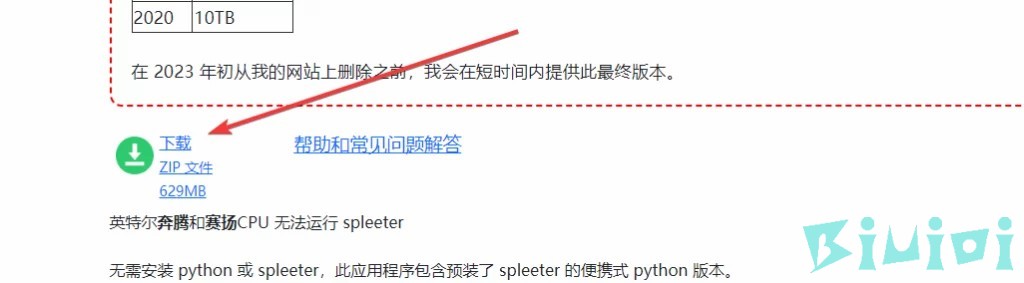
软件自带中文,总的来说还是很方便的。
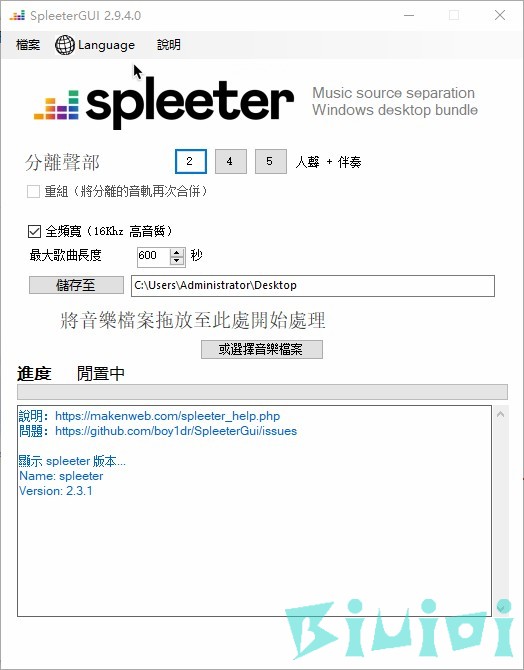
试试代码?
在线提取(需要科学上网环境)
想试用但不想安装任何东西?官方已为我们建立了一个Google Colab。
首先打开spleeter的GitHub页面
找到向下滑找到Quick start选择底下的Google Colab
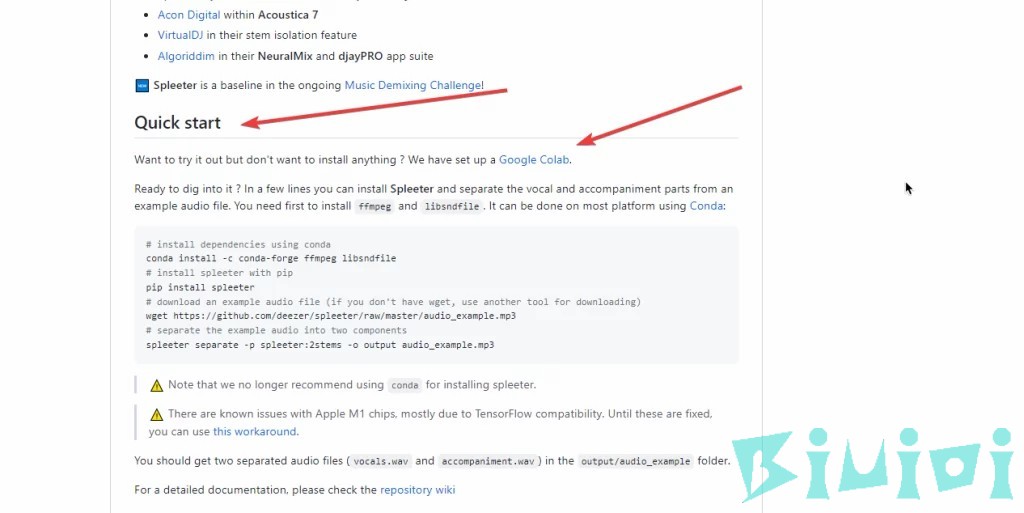
会提示授权,直接同意即可。
\[\*\*\]和绿色对勾,因为我执行过一遍),执行完成后会返回实例音频的分离结果。
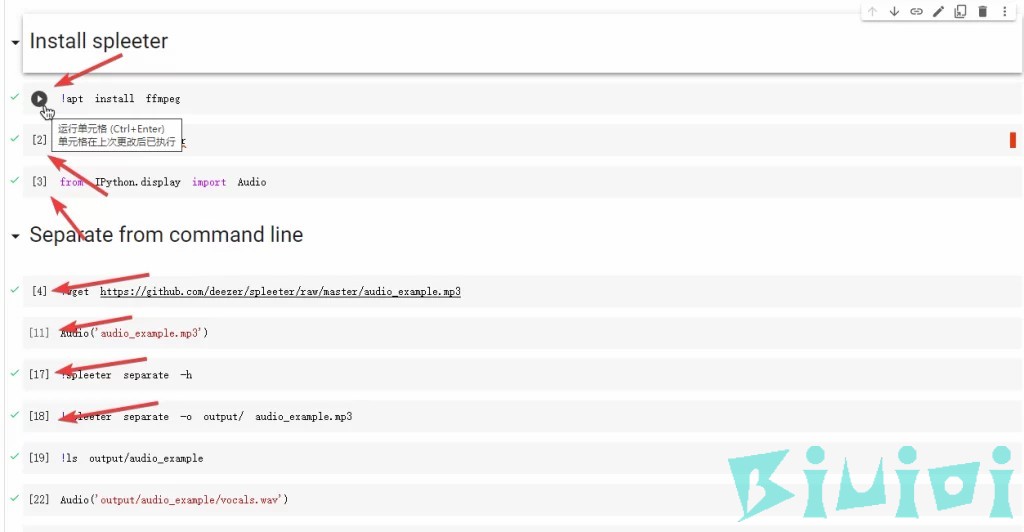
接下来我们分离自己的音频。
打开代码文件夹,删除audio_example.mp3 文件并把你要分离人声的音乐文件(mp3格式)上传到此目录下并重命名为audio_example.mp3 (如下图)
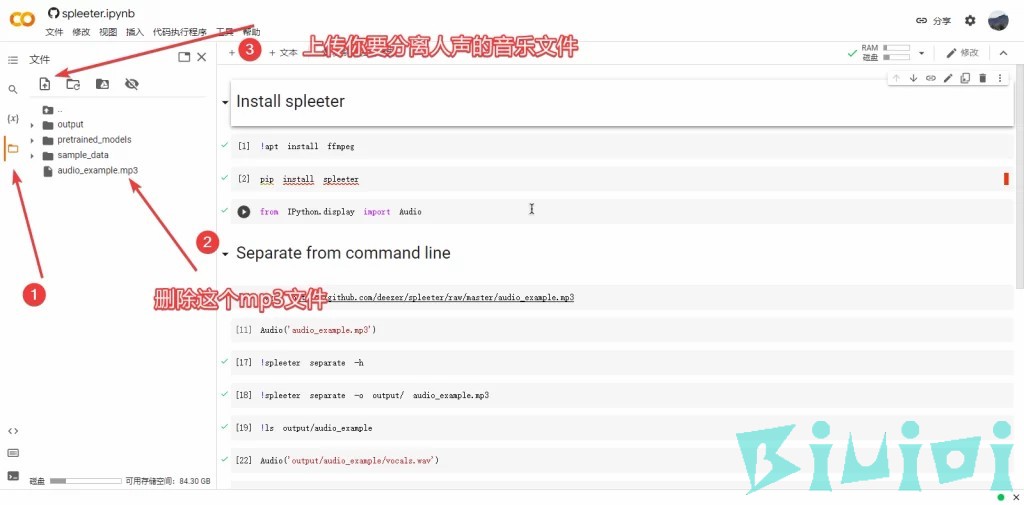
上传完成后,不用执行Install spleeter 内的的代码(也就是上面那三个),直接从Separate from command line 内的第三个代码开始执行。
等待命令全部执行,音乐和人声就分离出来了,有时会遇到下面问题。

解决方法是打开下方目录, vocals.wav就是你刚才分离的人声文件,accompaniment.wav 是背景音乐文件,直接右键下载即可。
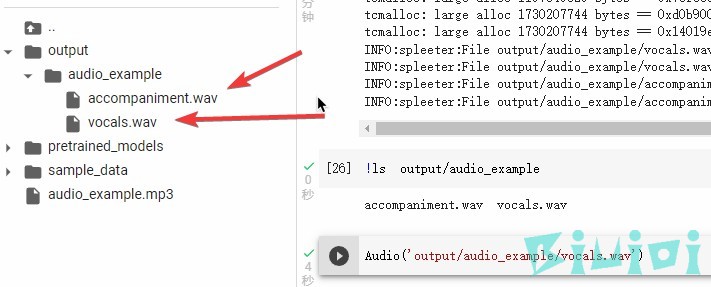
此时,你已经成功分离了人声和背景音乐。
本地分离
https://github.com/deezer/spleeter/wiki 去他们的wiki看看吧,这里偷个懒,我就不演示了。
φ(* ̄0 ̄)
绘制声波波幅图像
打开PyCharm,假设你会用PyCharm。
新建一个文件夹,在里面,新建一个test.py文件和audio文件夹,把你刚才提取的人声(名字为vocals.wav 不要改名字)放进audio文件夹,venv和.idea 不用创建PyCharm会自己创建。

安装软件包
用PyCharm打开test.py文件,安装下方软件包。
-
praat-parselmouth
-
numpy
-
matplotlib
-
seaborn
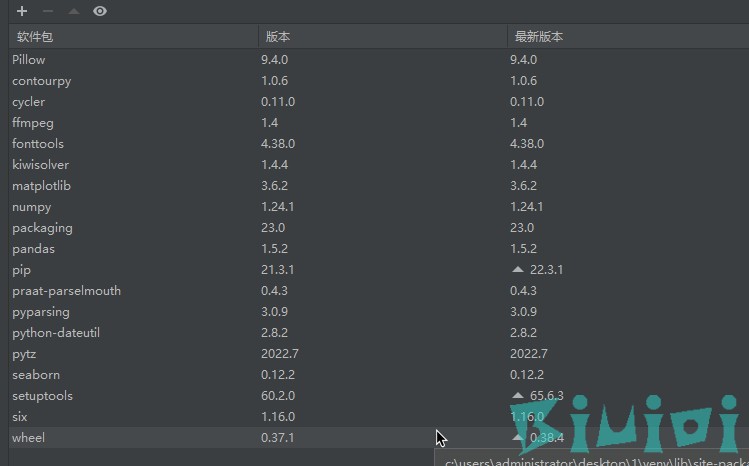
最后安装成下面这样就差不多,只用去安装上面四个,他会自动帮你安装下面那一堆。
获取音频图像
输入下方代码并执行
|
|
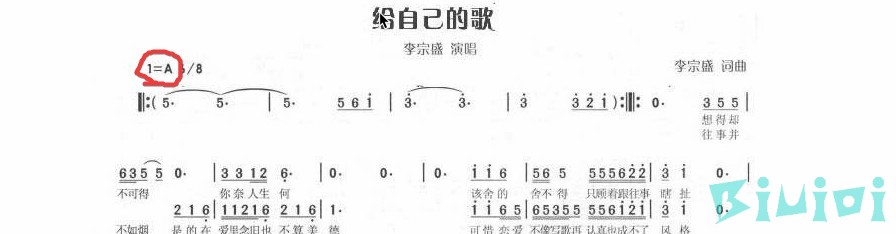
我们以给自己的歌 (Live) - 李宗盛这首歌来举例,首先我们要知道这首歌是什么调的,直接百度给自己的歌谱子,画圈的便是这首歌的调,可以看到是A调。
或者你可以用QQ音乐的智能曲谱,右键相关歌曲,随便选一个乐器,生成的谱子右上方写了歌曲的原调。
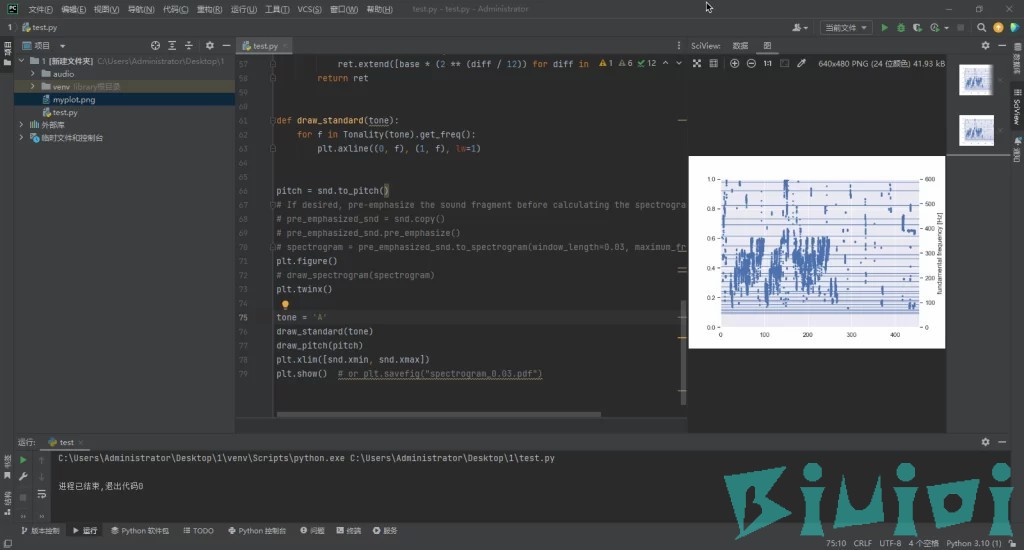
当我们知道了这首歌的调,接下来修改代码,代码第43行,这是代码可以分析的调。

来到代码第75行,我们已经知道了刚才的歌是A调,填入即可。

执行成功截图,右键最右边那一溜可以保存图像,由于我用了整首歌,所以这个图看起来特别密集,你可以截取相关片段来进行分析。
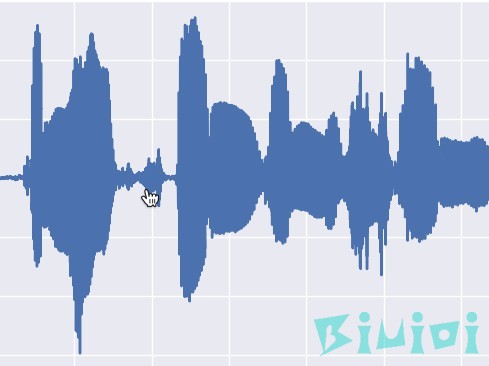
Parselmouth当前支持8类:声音,频谱,频谱图,强度,音高,共振峰,谐波和MFCC(以及它们之间的转换),例如:
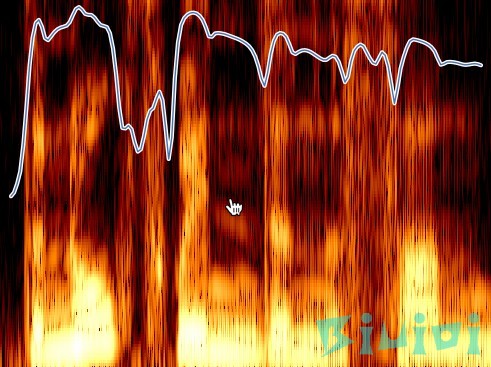
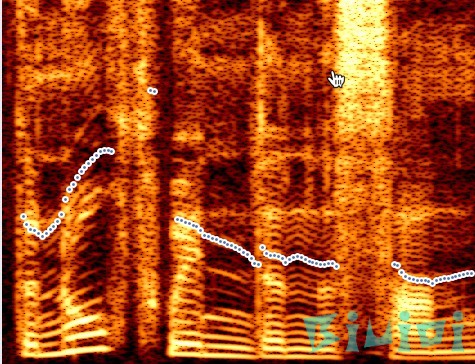
你可以访问它的GitHub页面获取相关代码。由于本人不懂乐理知识,所以这个图也看不懂,也无法给出建议,教程至此,快去试试吧。